Functions describe the world!
──by Thomas Garrity

screenshotted from IAS YouTube Video
函數能夠表達世界上的任何事情。只要我們能夠有足夠多的參數,無論是物體下一刻會在哪個地方、幾分鐘後會下雨、一週後的股價,這些都是能夠透過一個函數得知的。
在過去機器學習尚未出現的階段,人們會試圖減少問題當中存在的參數,或是創造一個理論上的狀態,去思考簡化後的問題會得出怎樣的答案。而在電腦出現後,人們開始把解決問題的方法變成一套 演算法,接下來交由電腦來找出答案。
不過,並不是所有的問題都能夠如此輕易被化簡,並沒有一套邏輯能夠直接地解出答案。例如將日語翻譯成中文這種定義較明確的問題,或是選擇考試或推甄哪個對未來比較好這種模稜兩可的問題,往往我們無法設計出一個好的算法。
反過來說,如果一個函數盡可能地複雜,那就有辦法表達世界上的任何答案。
機器學習本質上就是一個十分複雜的函數。透過這些過分複雜的關係,試圖去近似到目標問題的函數。
所以現在我們不去思考怎麼解決問題本身,而是思考如何設計一個足夠複雜、又能在任意情況下解決問題的 模型。
舉例來說,我們想分類收到的郵件是否為垃圾信件。
想法一如同專家系統,試圖以人去找到垃圾郵件的特徵,然後嘗試寫下程式判斷這些特徵是否存在。但往往過於耗時且難以與時俱進,並不是一個好作法。
想法二如同監督式學習,試圖標記資料,然後嘗試撰寫出一個機器模型,讓機器依照這些標記好的資料"學習"。這也就是在這次系列文章中會大大探討的領域。
想法三如同非監督式學習,只蒐集而不標記資料,然後嘗試撰寫一個機器模型,讓機器自己"學習"怎麼把這些資料分類。
想法四如同工人智慧,直接交給人來解決,有時會在一些權衡下認為人比機器還便宜的狀況下看到(X
像這種郵件的問題,我們可以當成是 分類問題(Classification Problem) ,畫在圖上就像這樣。

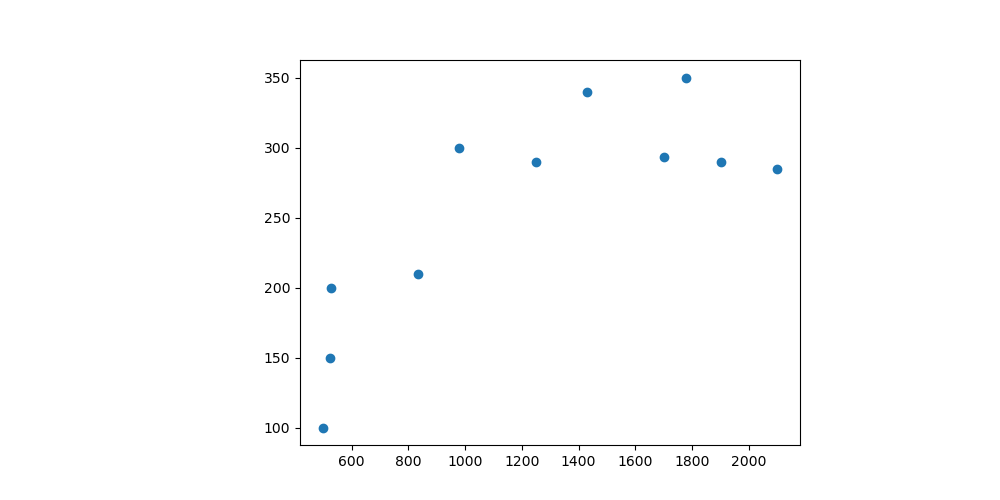
另一個例子是預測房價。依照非監督式學習的想法,我們會蒐集許多的資料,也許去看看房子大小與價格之間的關係如下。而機器學習做的就是試圖找到一個"不錯的"函數來表達,也就能拿來預測。
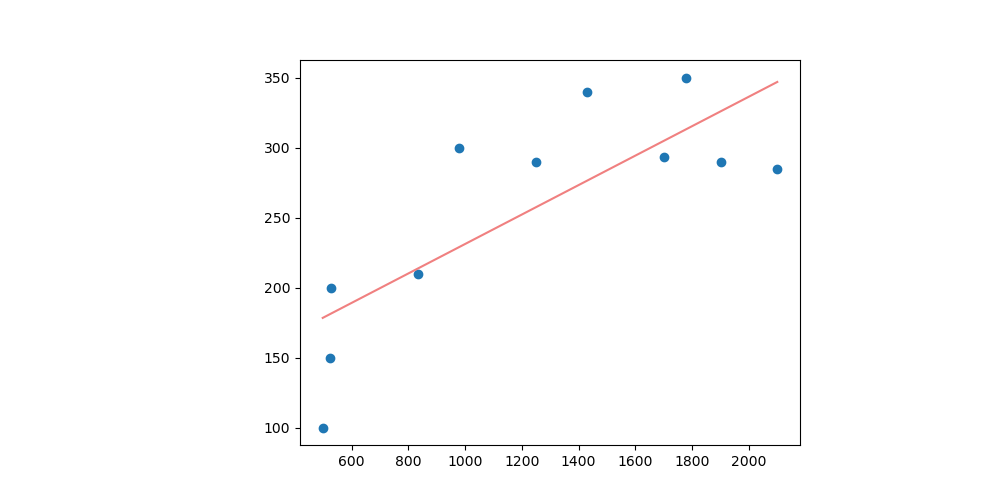
經過一些神祕的步驟,你也許可以找到一條不錯的直線來表達這個函數,例如 。這種可以透過簡單多項式去貼合問題的解決方法被稱為 迴歸分析(Regression) 。
至此我們簡單說明了機器學習是什麼,也認識到機器學習看起來是個相當有潛力的解決方案,畢竟 Functions describe the world, and model describe any functions。機器學習的模型只要能夠表達任意的函數,那問題都能透過機器學習解決了。

